Tot nu toe hebben we uitsluitend query's gezien waarbij informatie werd verwacht met betrekking tot individuele rijen uit de tabellen. Het komt echter regelmatig voor dat we geïnteresseerd zijn in geaggregeerde informatie. Hiermee wordt bedoeld informatie die niet meer is gebaseerd op afzonderlijke rijen, maar op verzamelingen van rijen. Rijen die op een bepaalde manier bij elkaar horen.
Stel bijvoorbeeld dat we een overzicht willen van het gemiddelde salaris (salary) van elke afdeling (department_id). Bij dit soort query's hebben we de GROUP BY component van het SELECT commando nodig. Voor het gemak hebben we de gemiddelde salarissen alvast afgerond.
SELECT ROUND(AVG(salary))
FROM employees
GROUP BY department_id;

Nu zegt zo'n overzicht met enkel gemiddelde salarissen niet zo veel. Je ziet niet meteen waar die gemiddelde salarissen op slaan. Daarom zetten we er een kolom bij die aangeeft welke afdeling (department_id) bij welk gemiddelde salaris hoort.
SELECT department_id, ROUND(AVG(salary))
FROM employees
GROUP BY department_id;
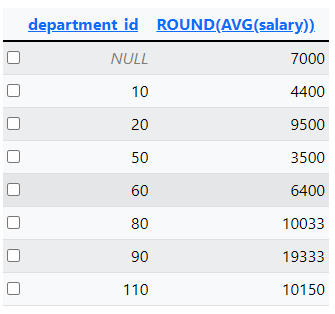
De rijen worden eerst gegroepeerd op department_id en daarna wordt de AVG functie (gemiddelde) toegepast op elke groep.
Of stel dat je het maximum salaris wil weten van elke afdeling. Eerst een overzicht zonder de afdelingsid's.
SELECT MAX(salary)
FROM employees
GROUP BY department_id;

Om te laten zien welk maximum salaris bij welke afdeling hoort, voeg je het department_id toe op de SELECT regel.
SELECT department_id, MAX(salary)
FROM employees
GROUP BY department_id;
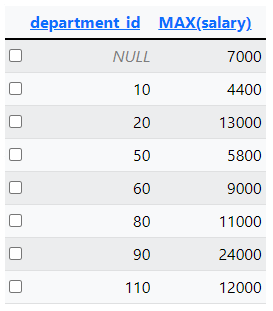
Als je een groepsfunctie gebruikt op de SELECT regel voorafgegaan door een kolomnaam, dan moet die kolomnaam genoemd worden op de GROUP BY regel.
Dus als er staat SELECT department_id, MAX (salary) op de SELECT regel, dan moet op de GROUP BY regel staan GROUP BY department_id.
De syntaxis is altijd in deze volgorde:
SELECT kolomnaam, groepsfunctie
FROM tabel
WHERE
GROUP BY kolomnaam
HAVING
ORDER BY
Voorbeeld: Tel het aantal per job_id. Maar IT_PROG mag niet voorkomen in het overzicht en alleen de job_id's die meer dan één keer voorkomen mogen worden getoond.
SELECT job_id, COUNT(job_id)
FROM employees
WHERE job_id <> 'IT_PROG'
GROUP BY job_id
HAVING COUNT(*) > 1
ORDER BY COUNT(job_id);

Je mag een alias (AS) gebruiken op de GROUP BY of de ORDER BY regel.
SELECT job_id AS functie, COUNT(job_id) AS aantal
FROM employees
WHERE job_id <> 'IT_PROG'
GROUP BY functie
HAVING COUNT(*) > 1
ORDER BY aantal DESC;
