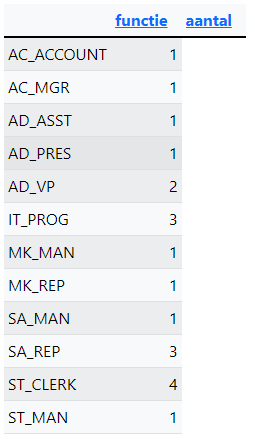
Query 1: Maak onderstaand overzicht na. Er is niet gesorteerd, maar let op de kolomnamen. Er is een telling gemaakt van de job_id's van de tabel employees.
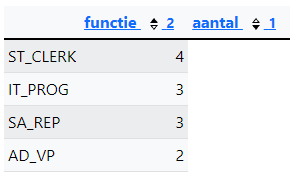
Query 2: Breid de query uit zodat je het volgende overzicht krijgt. Er is gesorteerd op aantal van hoog naar laag op de kolom met de aantallen en daarna alfabetisch op functie. Enkel de rijen met een aantal groter dan 1 moeten getoond worden.
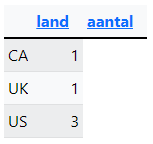
Query 3: Maak onderstaand overzicht na. Let op de kolomnamen. De informatie komt uit de tabel locations. Er is niet gesorteerd.
Query 4: Maak onderstaand overzicht na. Het is een overzicht van de department_id's met de aantallen. De informatie komt uit de tabel employees.
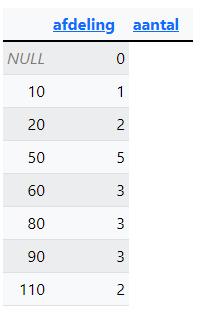
Query 5: Pas de query van opdracht 4 aan zodat je onderstaand overzicht krijgt. Enkel de afdelingen met een aantal van meer dan twee moeten worden geselecteerd. Er is gesorteerd op aantal van hoog naar laag en daarna op afdeling.
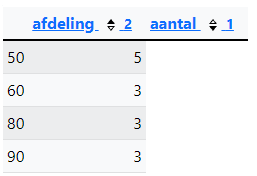
Query 6: We passen de query nog verder aan. De afdelingen waar 'King' of 'Hunold' werken, mogen niet meetellen. Die afdelingen weet je niet en je mag die niet "met de hand" opzoeken in de lijst, maar je kunt die nummers opvragen in een subquery. Hieronder zie je dat de afdelingen 60 en 90 niet meer worden getoond, maar je mag die informatie dus niet zomaar gebruiken, die moet je met een subquery opzoeken.
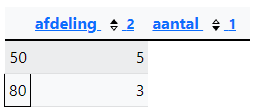
Query 7: Maak onderstaand overzicht na. Het zijn de department_id's met de totale salarissen die daar bij horen. De informatie komt uit de tabel employees.
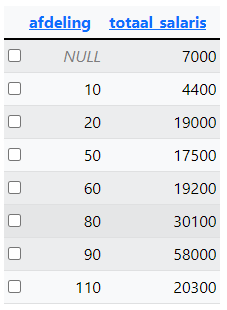
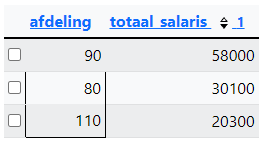
Query 8: Pas de query van opdracht 7 aan. De afdeling die NULL is mag niet meer meetellen. Enkel de afdelingen met meer dan 20.000 totaal moeten in beeld komen en er is gesorteerd op totaal_salaris van hoog naar laag.
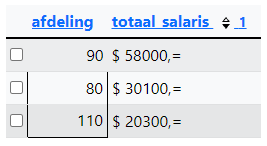
Query 9: Tenslotte gaan we de query van de opdrachten 7 en 8 nog een beetje aanpassen. Bij totaal_salaris moet er een dollarteken voor het bedrag komen, het bedrag is afgerond op nul decimalen en er staat een komma met een is-gelijk teken achter het bedrag.
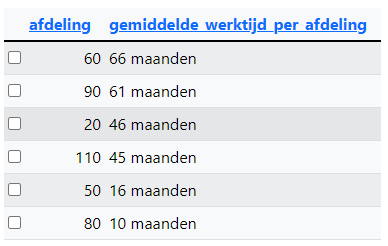
Query 10: Toon het gemiddeld aantal maanden dat er gewerkt is per afdeling. De informatie komt uit de tabel job_history. Er is gesorteerd van hoog naar laag op de tweede kolom. Je neemt het verschil tussen de datums start_date en end_date en daar moet het gemiddelde van worden getoond per department_id.